Many data logging systems for vehicles can be found on the market, from basic systems that only store the on-board communication for later evaluation, to more complex systems with radio-transmission and custom analog/digital measurement options. These systems almost always use the CAN bus communication protocol, which is the industry standard for on-board data communication due to its reliable messaging. However, the generic data acquisition systems do not know how to interpret data, so they simply log all messages that are placed on the CAN bus. This is not very user friendly, so we wanted the software architecture of our own data acquisition design, based on the National Instruments myRIO, to be a little more advanced.
A CAN message consists of an 8 or 11 bits ID (respectively non-extended and extended protocol). Every CAN device uses one or multiple IDs for the messages it can send and receive. The problem with just logging CAN messages is that many CAN devices are capable of changing its ID, which might be useful in case two devices cause a so called “ID collision”.
This means that two CAN messages that carry the same information type, that were logged at different moments, can have different CAN IDs. The software that reads out the logged messages is then not capable of interpreting both message logs in the same way.
Another issue with logging the complete CAN bus is that it is not possible to filter out certain message types that we do not need to know, causing unnecessary memory usage. Also, how to log data that is not transmitted through the CAN bus or is coming from an analog measurement?
In the following sections you can read about two approaches to the software architecture of the data acquisition and the designed file format. The complete system consists of two programs:
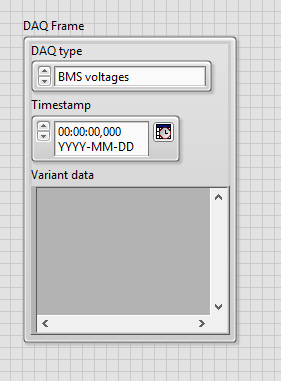 It contains the type of data, the timestamp when data was collected and the “Variant”. This variant could then be filled with anything, for example the voltage data, which is a cluster that contains 4 floating point numbers of BMS voltage measurements.
It contains the type of data, the timestamp when data was collected and the “Variant”. This variant could then be filled with anything, for example the voltage data, which is a cluster that contains 4 floating point numbers of BMS voltage measurements.
 The DAQ Frame cluster is a nice single object that can be placed in the “write queue”. The items in this queue are passed to a different thread that writes the data to a file, asynchronously. Writing a frame to the file boils down to the following Block Diagram:
The DAQ Frame cluster is a nice single object that can be placed in the “write queue”. The items in this queue are passed to a different thread that writes the data to a file, asynchronously. Writing a frame to the file boils down to the following Block Diagram:
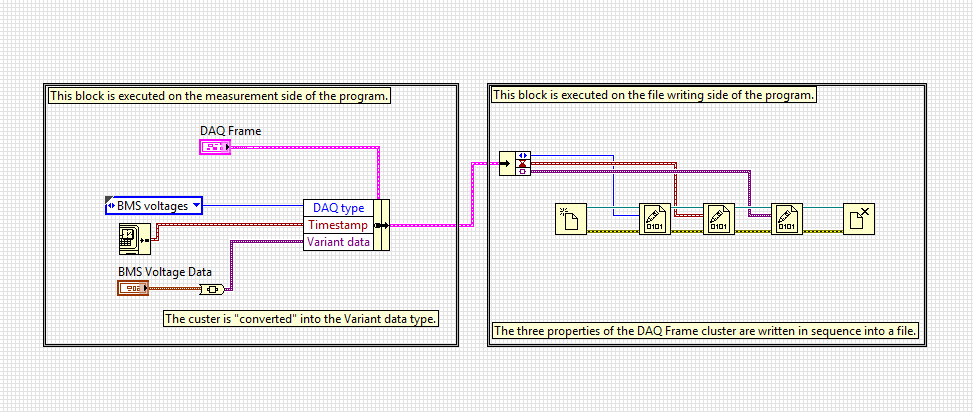 This (very simplified) block diagram seems to work very programmer friendly, as it is able to write any type of data to a file.
The main idea behind this implementation was that every measurement type that needs to be stored gets its own DAQ Type (which is an enum) and also its own cluster to be placed inside the variant of the DAQ Frame. This turned out to be actually very annoying to work with, mainly because the measurement cluster needs to be known and implemented both at the writing stage and when reading out the stored data file. This resulted in a lot of work to be done for each measurement type that was added. Also, when the measurement type was not yet implemented on the readout-side of the program, the amount of bytes to be read could not be determined. Well, LabVIEW probably could, but because variants and the Write to Binary File functions are really just black boxes, it was difficult to know what bytes were written exactly.
An additional disadvantage of this implementation was that the CAN messages (containing 64 bits at most) were converted on-board to floating point data (32 or 64 bits per number), for example when measuring the BMS voltages. This increased the file size without increasing the information carried by the file.
This (very simplified) block diagram seems to work very programmer friendly, as it is able to write any type of data to a file.
The main idea behind this implementation was that every measurement type that needs to be stored gets its own DAQ Type (which is an enum) and also its own cluster to be placed inside the variant of the DAQ Frame. This turned out to be actually very annoying to work with, mainly because the measurement cluster needs to be known and implemented both at the writing stage and when reading out the stored data file. This resulted in a lot of work to be done for each measurement type that was added. Also, when the measurement type was not yet implemented on the readout-side of the program, the amount of bytes to be read could not be determined. Well, LabVIEW probably could, but because variants and the Write to Binary File functions are really just black boxes, it was difficult to know what bytes were written exactly.
An additional disadvantage of this implementation was that the CAN messages (containing 64 bits at most) were converted on-board to floating point data (32 or 64 bits per number), for example when measuring the BMS voltages. This increased the file size without increasing the information carried by the file.
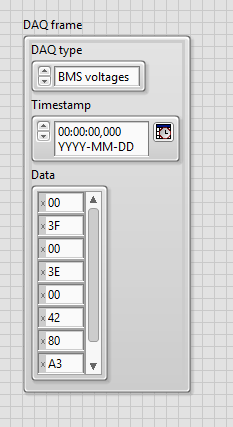 Here, the variant was replaced by a simple byte array. The byte array can be of any size. The DAQ Type property lets the readout software know how to interpret the bytes. Here the bytes will be inflated to, for example, floating point data that is more easily understandable by the user.
An advantage to this system is that it is actually easier to process CAN messages. All that needs to be done is to match a specific CAN identifier with the right DAQ Type and just store the bytes of the CAN frame into the DAQ Frame.
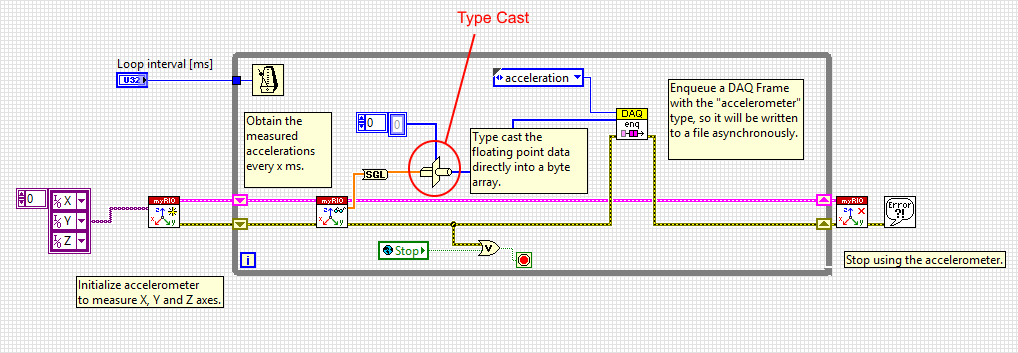
For other measurements that are not communicated over the CAN bus, it is a bit less straightforward to store them. Fortunately LabVIEW has a neat Type Cast function, that does a direct reinterpretation of data. For example the Acceleration measurement that simply uses the accelerometer built into the myRIO, as shown below. I have encircled the Type Cast function. In this case, the 64-bit floating point array is first converted into a 32-bit floating point array, whose binary data is then reinterpreted as a byte array.
Here, the variant was replaced by a simple byte array. The byte array can be of any size. The DAQ Type property lets the readout software know how to interpret the bytes. Here the bytes will be inflated to, for example, floating point data that is more easily understandable by the user.
An advantage to this system is that it is actually easier to process CAN messages. All that needs to be done is to match a specific CAN identifier with the right DAQ Type and just store the bytes of the CAN frame into the DAQ Frame.
For other measurements that are not communicated over the CAN bus, it is a bit less straightforward to store them. Fortunately LabVIEW has a neat Type Cast function, that does a direct reinterpretation of data. For example the Acceleration measurement that simply uses the accelerometer built into the myRIO, as shown below. I have encircled the Type Cast function. In this case, the 64-bit floating point array is first converted into a 32-bit floating point array, whose binary data is then reinterpreted as a byte array.
- The data acquisition program that runs on the myRIO that collects the data through measurements and the CAN bus.
- The readout program that runs on a computer that reads the files generated by the data acquisition and visualizes the data for the user.
The black box of Variants
By default LabVIEW has a very nice function, called Write to Binary File. This function is extremely user friendly because it accepts any type of data to be written in binary form to a file, from floating point numbers to arrays to the most complex clusters (similar to C structs). This is all made possible by the “Variant” data type, a set of data that contains both the type information and the data itself. The first approach of the data architecture uses these Variants in the following manner. A cluster called DAQ Frame was declared as follows:
It contains the type of data, the timestamp when data was collected and the “Variant”. This variant could then be filled with anything, for example the voltage data, which is a cluster that contains 4 floating point numbers of BMS voltage measurements.
The DAQ Frame cluster is a nice single object that can be placed in the “write queue”. The items in this queue are passed to a different thread that writes the data to a file, asynchronously. Writing a frame to the file boils down to the following Block Diagram:
This (very simplified) block diagram seems to work very programmer friendly, as it is able to write any type of data to a file.
The main idea behind this implementation was that every measurement type that needs to be stored gets its own DAQ Type (which is an enum) and also its own cluster to be placed inside the variant of the DAQ Frame. This turned out to be actually very annoying to work with, mainly because the measurement cluster needs to be known and implemented both at the writing stage and when reading out the stored data file. This resulted in a lot of work to be done for each measurement type that was added. Also, when the measurement type was not yet implemented on the readout-side of the program, the amount of bytes to be read could not be determined. Well, LabVIEW probably could, but because variants and the Write to Binary File functions are really just black boxes, it was difficult to know what bytes were written exactly.
An additional disadvantage of this implementation was that the CAN messages (containing 64 bits at most) were converted on-board to floating point data (32 or 64 bits per number), for example when measuring the BMS voltages. This increased the file size without increasing the information carried by the file.
Know your bytes
More control over the exact bytes written was necessary. In the first place to be sure the bytes could always be read (but maybe not yet interpreted) by the readout software, because the software knows it needs to read bytes instead of a specific type of cluster. In the second place to compress the file size. A quick realization of this architecture was to change the DAQ Frame cluster to the following:
Here, the variant was replaced by a simple byte array. The byte array can be of any size. The DAQ Type property lets the readout software know how to interpret the bytes. Here the bytes will be inflated to, for example, floating point data that is more easily understandable by the user.
An advantage to this system is that it is actually easier to process CAN messages. All that needs to be done is to match a specific CAN identifier with the right DAQ Type and just store the bytes of the CAN frame into the DAQ Frame.
For other measurements that are not communicated over the CAN bus, it is a bit less straightforward to store them. Fortunately LabVIEW has a neat Type Cast function, that does a direct reinterpretation of data. For example the Acceleration measurement that simply uses the accelerometer built into the myRIO, as shown below. I have encircled the Type Cast function. In this case, the 64-bit floating point array is first converted into a 32-bit floating point array, whose binary data is then reinterpreted as a byte array.